G-DReaM can be uniformly applied to heterogeneous embodiments without requiring their motion data, even when their skeletons are non-homeomorphic.
Abstract
Motion retargeting for specific robot from existing motion datasets is one critical step in transferring motion patterns from human behaviors to and across various robots. However, inconsistencies in topological structure, geometrical parameters as well as joint correspondence make it difficult to handle diverse embodiments with a unified retargeting architecture. In this work, we propose a novel unified graph-conditioned diffusion-based motion generation framework for retargeting reference motions across diverse embodiments. The intrinsic characteristics of heterogeneous embodiments are represented with graph structure that effectively captures topological and geometrical features of different robots. Such a graph-based encoding further allows for knowledge exploitation at the joint level with a customized attention mechanisms developed in this work. For lacking ground truth motions of the desired embodiment, we utilize an energy-based guidance formulated as retargeting losses to train the diffusion model. As one of the first cross-embodiment motion retargeting methods in robotics, our experiments validate that the proposed model can retarget motions across heterogeneous embodiments in a unified manner. Moreover, it demonstrates a certain degree of generalization to both diverse skeletal structures and similar motion patterns.
Overview
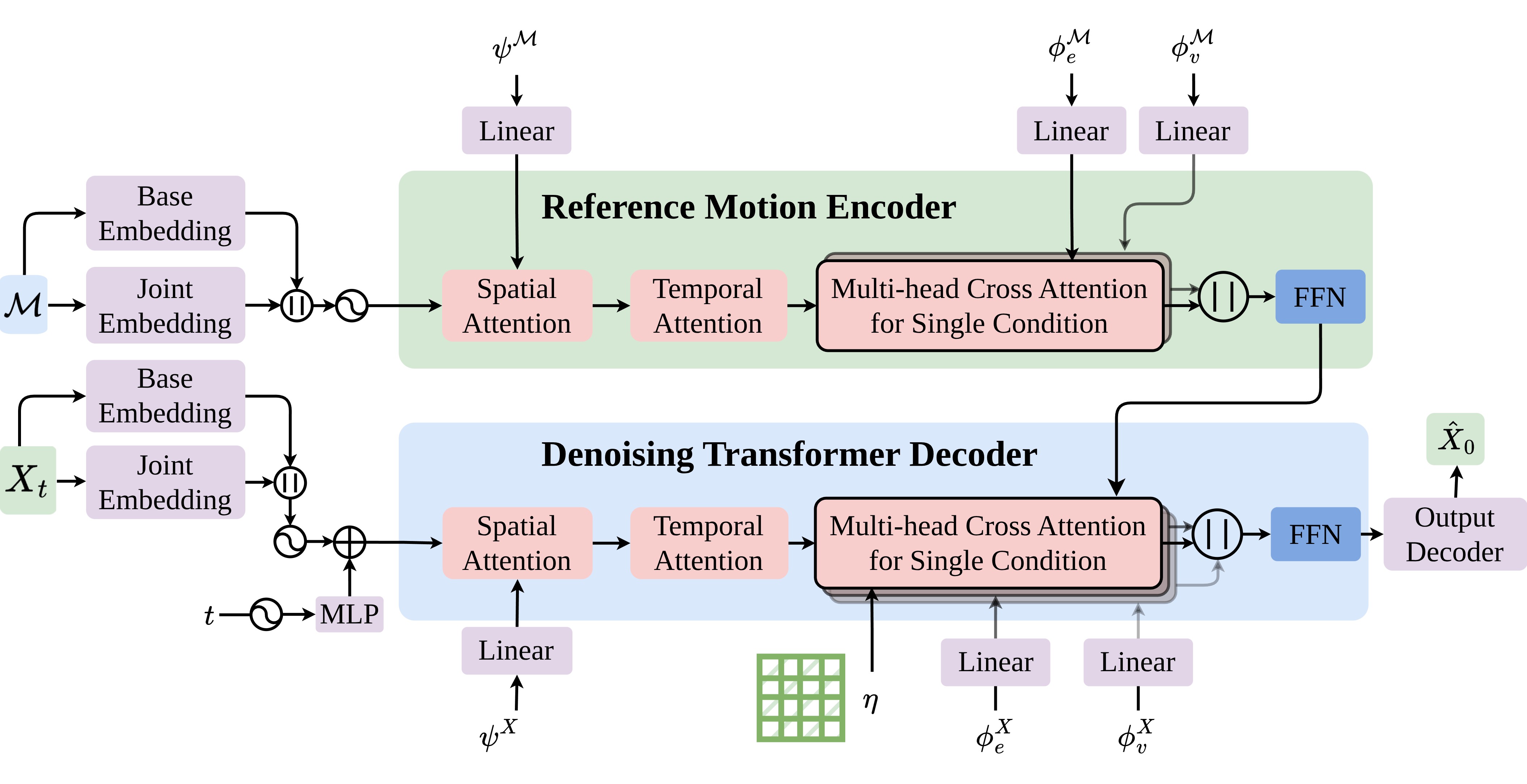
The denoising network is based on a transformer decoder with a noisy motion input \(X_t\) under the conditions of the reference motion \(\mathcal{M}\) and graphs \(g^{\mathcal{M},X} = \{ \phi_v^{\mathcal{M},X}, \phi_e^{\mathcal{M},X},\psi^{\mathcal{M},X}\}\). The input motion is tokenized at the joint level, where the base joint and other joints are embedded by independent encoders. Then spatial and temporal attentions extract the relationships between all joints and the chronological relationships along the time window. In addition, the spatial attention absorb the joint connectivity \(\psi\) to enrich the joint relationships. For other graphic conditions, we use a multi-conditional cross attention to treat them individually. In particular, the reference motion condition \(\mathcal{M}\) is encoded using a similar transformer decoder and incorporates the joint correspondence \(\eta\) as an attention mask. Finally, the predicted motion \(\hat{X}_0\) is output from a output decoder.
Multi-Embodiment Motion Retargeting
By leveraging graph structures, G-DReaM encodes both topological and geometric features of diverse robotic embodiments, allowing it to retarget motions across robots with varying link lengths, joint numbers, kinematic chains, and end-effectors in a unified way.
Fight
Reference
Atlas
CL
G1
H1
Tron
Cassie
Kick
Reference
Atlas
CL
G1
H1
Tron
Cassie
Stand Up
Reference
Atlas
CL
G1
H1
Tron
Cassie
Throw Ball
Reference
Atlas
CL
G1
H1
Tron
Cassie
Stagger
Reference
Atlas
CL
G1
H1
Tron
Cassie
Embodiment Generalization
(Link Length Aspect)
G-DReaM demonstrates zero-shot generalization across embodiments with varying link lengths. The retargeted motion will be automatically adjusted to fit the specific link length, enabling better imitation of the reference motion.
Unscaled Case
Scaled Case
Here, we remove the joint correspondence of the knee for a more distinct comparative result. When the calf length is increased (right), the robot tends to bend its knee more to better track the reference position of the ankle joint.
Embodiment Generalization
(Joint Correspondence Aspect)
G-DReaM demonstrates zero-shot generalization across embodiments with controllable joint correspondences. The retargeted motions can be automatically adjusted to align with the specified joint mappings.
Without Correspondence
With Correspondence
Here, we choose a scaled calf length setting to produce a more distinct comparative result. The green joints indicate those that are required to match the reference motion, while the red joints are not constrained. The results show that the generated motion adapts to better track the joints with defined correspondences. When the knee joint is unconstrained (left), the robot bends its knee to better align the ankle joint under the scaled configuration.
Embodiment Generalization
(Model Adaptation for New Embodiments)
For diverse unseen embodiments, G-DReaM can adapt the pretrained model to new skeletons by conditioning it on new skeleton graphs during training, while keeping the original dataset unchanged. Here, we show the retargeted results of the adapted model on new robots \(\textit{Talos}\) and \(\textit{Valkyrie}\).
Fight
Reference
Talos
Valkyrie
Kick
Reference
Talos
Valkyrie
Stand Up
Reference
Talos
Valkyrie
Throw Ball
Reference
Talos
Valkyrie
Stagger
Reference
Talos
Valkyrie
Motion Generalization
G-DReaM also demonstrates zero-shot generalization to unseen motions. Specifically, we show that our model can successfully handle unseen motion sequences from the LAFAN1 Retargeting dataset.
Unseen Motion: Jump
Reference
Atlas
CL
G1
H1
Tron
Cassie
Unseen Motion: Kick
Reference
Atlas
CL
G1
H1
Tron
Cassie
Unseen Motion: Run
Reference
Atlas
CL
G1
H1
Tron
Cassie
Unseen Motion: Walk
Reference
Atlas
CL
G1
H1
Tron
Cassie